Etcd 是什么
Etcd 是什么
Etcd 是一个分布式键值存储系统,被设计用于可靠地存储和检索关键数据,以支持分布式系统的协调和一致性。它是由 CoreOS 开发的开源项目,现在是云原生计算基金会(CNCF)的一部分。
Etcd 提供了一个简单的键值数据模型,类似于一个分布式的字典或数据库。它的特点包括:
分布式一致性:Etcd 使用 Raft 算法作为其一致性协议,确保数据在不同节点之间的一致性。这使得 Etcd 在面对网络故障、节点故障或网络分区时,仍能保持一致性。
高可用性:Etcd 可以通过复制数据到多个节点来提供高可用性。即使其中一些节点发生故障,系统仍然可以继续工作,因为数据可以从其他节点获取。
快速响应:Etcd 使用基于内存的数据结构和高效的读写路径,以实现快速的数据访问和响应。
监听与通知:Etcd 提供了监听机制,可以订阅特定键的更改通知。这使得应用程序可以实时获取关键数据的变化,以便做出相应的响应。
Etcd 主要用于构建分布式系统和云原生应用程序,用于存储共享配置、服务发现、分布式锁、领导选举和协调等方面。它在 Kubernetes 集群中广泛使用,作为其底层的分布式数据存储,用于存储集群状态、配置信息和元数据。
Etcd 如何保持高可用性
Etcd 实现高可用性的关键在于其分布式设计和数据复制机制。下面是 Etcd 如何保持高可用性的主要原理:
Raft 一致性算法:Etcd 使用 Raft 算法作为其一致性协议。Raft 算法通过选举一个领导者节点,并使用心跳机制来保持领导者和其他节点之间的一致性。在 Etcd 集群中,领导者负责接收写操作并将其复制到其他节点,从而实现数据的一致性和复制。
数据复制和复制日志:Etcd 将数据复制到多个节点以实现高可用性。当领导者节点接收到写请求时,它会将写操作转化为一个复制日志项,并将该日志项发送给其他节点。其他节点接收到日志项后,将其应用到本地存储中,从而实现数据的复制和同步。
快速故障检测和恢复:Etcd 集群使用心跳机制来定期检测节点的存活状态。如果一个节点停止发送心跳信号,其他节点将会将其标记为不可用,并启动选举过程选择新的领导者。这样可以快速检测到故障节点并进行自动恢复。
自动数据重新分配:当新节点加入 Etcd 集群或节点发生故障时,Etcd 会自动进行数据重新分配。在新节点加入集群时,Etcd 会将部分数据复制到新节点以实现负载均衡和数据冗余。当节点发生故障时,Etcd 会将故障节点上的数据自动迁移到其他可用节点上,确保数据的可用性和一致性。
通过上述机制,Etcd 实现了高可用性。即使其中一个节点发生故障,其他节点可以继续提供服务,并保持数据的一致性。新节点的加入和故障节点的恢复都是自动进行的,无需人工干预。
值得注意的是,为了确保高可用性,Etcd 需要在一个分布式环境中运行,并建议以集群方式部署,使用多个节点来提供服务。通常,一个 Etcd 集群至少需要三个节点来保证容错性和多数派原则的有效性。
总而言之,Etcd 通过使用 Raft 一致性算法、数据复制和复制日志、快速故障检测和恢复以及自动数据重新分配等机制,实现了高可用性。这使得 Etcd 集群能够在节点故障或网络分区等情况下继续工作,并保持数据的一致性和可用性。
Etcd 选举机制
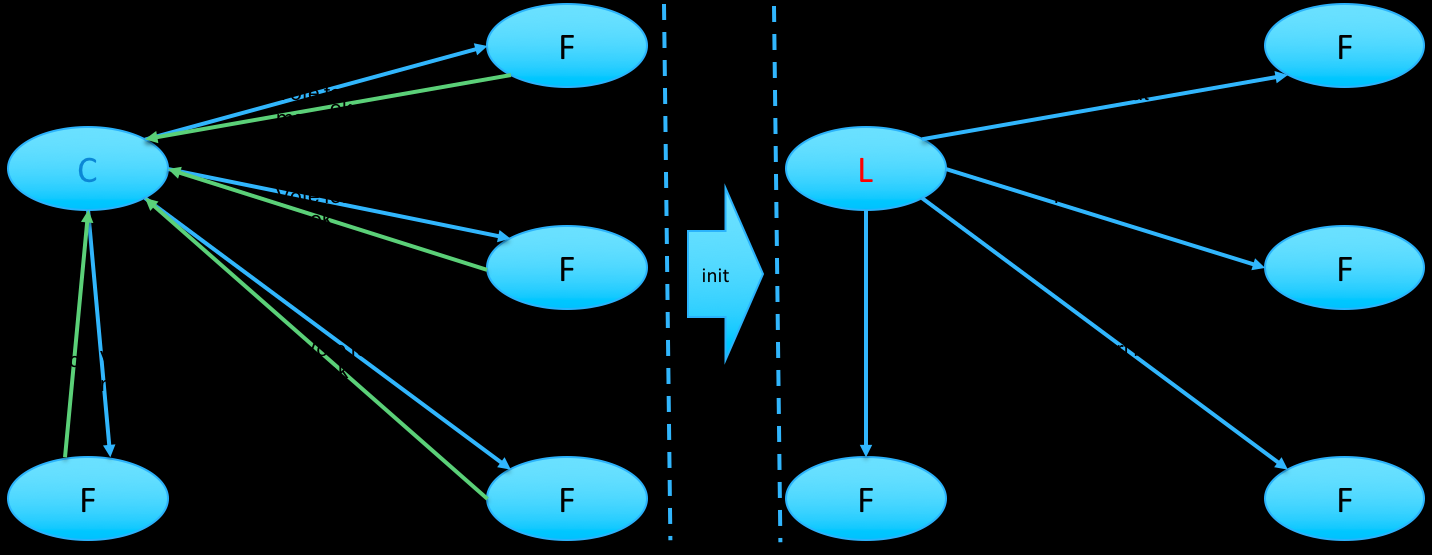
ETCD使用raft算法将一组主机组成集群,集群中的每个节点都可以根据集群运行的情况在三种状态间切换:follower, candidate 与 leader。leader 和 follower 之间保持心跳。如果follower在一段时间内没有收到来自leader的心跳,就会转为candidate,发出新的选主请求。
集群初始化的时候内部的节点都是follower节点,之后会有一个节点因为没有收到leader的心跳转为candidate节点,发起选主请求。当这个节点获得了大于一半节点的投票后会转为leader节点。
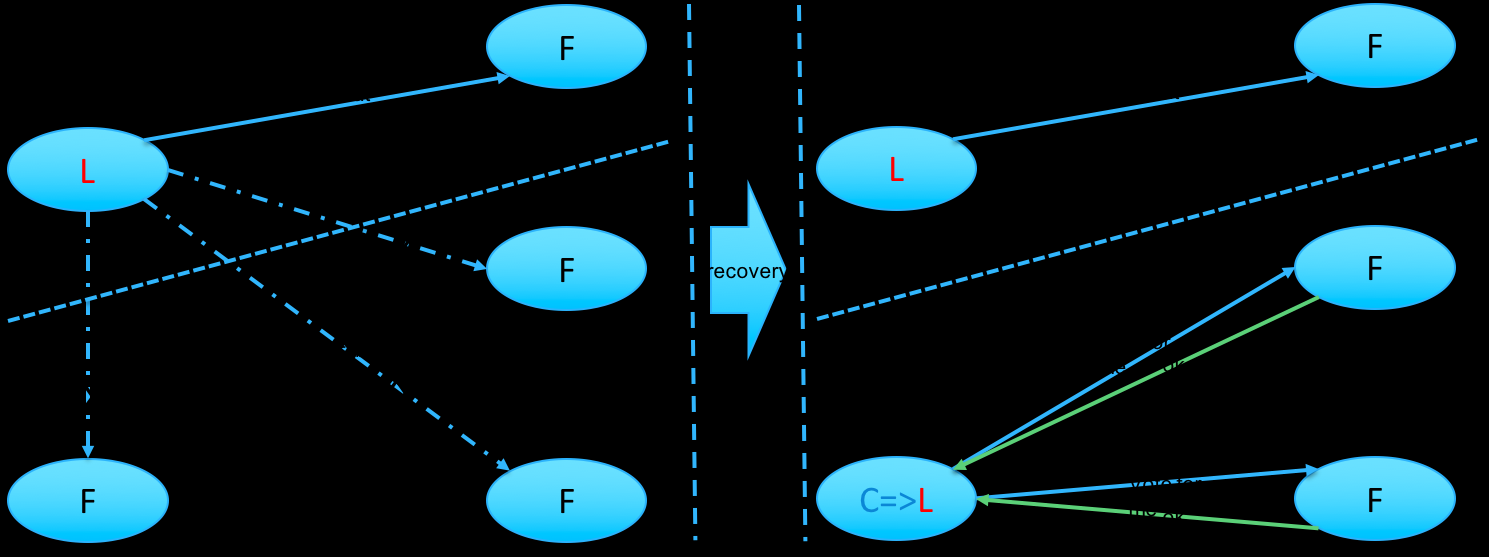
当 leader 节点服务异常后,其中的某个 follower 节点因为没有收到 leader 的心跳转为 candidate 节点,发起选主请求。只要集群中剩余的正常节点数目大于集群内主机数目的一半,ETCD集群就可以正常对外提供服务。

Etcd 脑裂如何解决
当集群内部的网络出现故障集群可能会出现“脑裂”问题,这个时候集群会分为一大一小两个集群(所以需要奇数节点的集群),较小的集群会处于异常状态,较大的集群可以正常对外提供服务。